��Ч�����l��ģʽ��(sh��)���㷨�о�
���ٙ�Ŀ��Ӌ(j��)��C(j��)��(y��ng)��Փ�� �l(f��)�����ڣ�2011-02-05 19:29 ��ȣ�
����ժҪ���l��ģʽ��(sh��)�������������ھ�Ч�ʣ����P(gu��n)(li��n)Ҏ(gu��)�t�ھ�ʷ�ϵ�һ��(g��)�v�̱����l��ģʽ���L(zh��ng)�㷨�ڄ�(chu��ng)���l��ģʽ��(sh��)�r(sh��)���؏�(f��)���^�½Y(ji��)�c(di��n)�c�ѽ�(j��ng)����Y(ji��)�c(di��n)���Ա�_���²����c(di��n)��λ�ã�����������ϵ����M(f��i)��ᘌ�(du��)�ˆ�(w��n)�}���������һ�N��Q���������ڄ�(chu��ng)��FP-tree֮ǰ����ÿһ��(w��)�D(zhu��n)�Q������(y��ng)�Č�(sh��)��(sh��)���Ա���ͨ�^(gu��)�(xi��ng)�^�팤�ҽY(ji��)�c(di��n)朕r(sh��)���Կ��ٶ�λ��Ȼ���ٌ�(du��)�@Щ�Ɍ�(sh��)��(sh��)�M�ɵČ�(du��)��(y��ng)��(sh��)��(j��)��(k��)�M(j��n)�����õ�һ��(g��)�µĔ�(sh��)��(j��)��(k��)�����µĔ�(sh��)��(j��)��(k��)���A(ch��)�Ͽ��������l��ģʽ��(sh��)���@�Ӿͱ����˴������؏�(f��)�Ĺ���������˄�(chu��ng)��FP-tree��Ч�ʡ���Փ�����������ĺ���㷨���������@��(y��u)��ԭ�㷨��
�����P(gu��n)�I�~����(sh��)��(j��)�ھ��l���(xi��ng)���ھ��l��ģʽ���L(zh��ng)�㷨�������l��ģʽ���L(zh��ng)�㷨��
�����ЈD���̖(h��o)��TP311.1
����1����
�����l��ģʽ���ھ�[1]���P(gu��n)(li��n)Ҏ(gu��)�t[2]�����P(gu��n)����������ģʽ������ɡ��@¶ģʽ���S����Ҫ��(sh��)��(j��)�ھ��΄�(w��)�гГ�(d��n)����Ҫ�Ľ�ɫ���L(zh��ng)���ԁ�(l��i)���ھ��l��ģʽ��Ҫ����Apriori[3,4]�㷨������M(j��n)��ʽ��Ȼ��Apriori������M(j��n)�㷨��Ȼ��(hu��)�a(ch��n)���������x�(xi��ng)��������Ҫ����(f��)�l���Ē��蔵(sh��)��(j��)��(k��)���@��(y��n)��Ӱ����㷨��Ч�ʡ�J.Han����������µĽY(ji��)��(g��u)FP-tree������(y��ng)��ģʽ���L(zh��ng)�㷨FP-growth[5]��ԓ�㷨���÷��εIJ��ԣ��o(w��)횮a(ch��n)�����x�(xi��ng)����F(xi��n)P-growth�㷨��һ�N���|(zh��)�ϲ�ͬ��Apriori���ھ��l���(xi��ng)������Ч�㷨�������Ĵ֕r(sh��)�g�����M(f��i)��FP-tree���l��FP-tree�Ę�(g��u)���c��v�ϣ����������@�����Ч�ʌ���(du��)����㷨��Ч�����^��Ď����������@�ӵķ������҂�����ˌ�(du��)FP-growth�㷨�ĸ��M(j��n)��ʩ����ԭ��(sh��)��(j��)��(k��)D�Ļ��A(ch��)�Ͻ����µĔ�(sh��)��(j��)��(k��)D*���Աㄓ(chu��ng)������FP-tree��ʹ�Ø�(sh��)�е�ÿһ��(g��)�Y(ji��)�c(di��n)���ӽY(ji��)�c(di��n)�����(xi��ng)����̖(h��o)��С�������С��@�ӣ������½Y(ji��)�c(di��n)�r(sh��)��Ҫ���^�ĽY(ji��)�c(di��n)��(sh��)����ˣ��Ķ��s�̘�(g��u)��һ�Ø�(sh��)�ĕr(sh��)�g�����⣬߀��ȡ�������ă�(y��u)����ʩ���猢item-no����item-name�Ĵ����ų�һ��(g��)�б����ڌ�item-name�D(zhu��n)�Q��item-no�r(sh��)��ͨ�^(gu��)�б���ֱ���ҵ���(du��)��(y��ng)���(xi��ng)��
����2��(w��n)�}����
����2��1�l���(xi��ng)��[6]
�����O(sh��)I={i1,i2,…,in}��n��(g��)��ͬ�(xi��ng)Ŀ��Item���ļ��ϣ������(du��)һ��(g��)���ϣ���k=|X|,�tX�Q��K�(xi��ng)�������ߺ�(ji��n)�εطQ��һ��(g��)�(xi��ng)����Itemset����ӛD����(w��)T�ļ��ϣ�����(du��)�ڽo����(w��)��(sh��)��(j��)��(k��)D�����xX��֧�ֶȞ�D�а���X����(w��)��(g��)��(sh��)��ӛ��sup(X)���Ñ����Զ��xһ��(g��)С��|D|����С֧�ֶ�ӛ��s.
�������x1�l���(xi��ng)�����o����(w��)��(sh��)��(j��)��(k��)D��֧�ֶ�s����(du��)���(xi��ng)������sup(X)≥s,�t�QX��D�е��l���(xi��ng)����
�������|(zh��)1һ��(g��)�L(zh��ng)�Ȟ�k���(xi��ng)�������l���ģ��t�����L(zh��ng)�Ȟ飨k+1���ij�ģʽ���������l���ġ�
����2.2FP-tree��FP-growth�㷨
�����l��ģʽ��(sh��)��FP-tree�У�ÿ��(g��)�Y(ji��)�c(di��n)��3��(g��)��M�ɣ��(xi��ng)��item���Y(ji��)�c(di��n)֧�ֶ�Ӌ(j��)��(sh��)sup-count���Y(ji��)�c(di��n)�node-link���鷽���v����(chu��ng)��һ��(g��)�(xi��ng)�^��Headertable������2��(g��)��M��:�(xi��ng)��item�ͽY(ji��)�c(di��n)��^headofnode-link�����нY(ji��)�c(di��n)��^ָ��FP-tree���c֮���Q��ͬ�ĵ�һ�Y(ji��)�c(di��n)��
����FP-growth�㷨��Ҫ��FP-tree�Ę�(g��u)���^(gu��)�̣���Ҫ����ɴΔ�(sh��)��(j��)��(k��)��
����(1)��һ�Β��蔵(sh��)��(j��)��(k��)D���a(ch��n)�������l��1-�(xi��ng)������֧�ֶ�Ӌ(j��)��(sh��)������֧�ֶȽ������в��˵��(xi��ng)�^����
����(2)��(chu��ng)��FP-treeT�ĸ��Y(ji��)�c(di��n)����“null”��(bi��o)ӛ����(du��)D��ÿ��(g��)��(w��)������̎��:�ٰ��(xi��ng)�^���еĴ������е�һ�Β���õ����l���(xi��ng)�����O(sh��)���к�ĽY(ji��)����[p|P]������p�ǵ�1��(g��)�(xi��ng)Ŀ����p��ʣ���(xi��ng)Ŀ���б�;���{(di��o)��insert_tree[p|P]�����T����ŮNʹ��N.item=p���tN��Ӌ(j��)��(sh��)����1����t��(chu��ng)��һ��(g��)�½Y(ji��)�c(di��n)N���������Qitem�O(sh��)�Þ�p����sup_count�O(sh��)�Þ�1��朽ӵ����ĸ��Y(ji��)�c(di��n)����ͨ�^(gu��)�Y(ji��)�c(di��n)�node-link朽ӵ�������ͬ�(xi��ng)���ĽY(ji��)�c(di��n)�����P�ǿգ��f�w�{(di��o)��insert_tree([P|N])��
����3�����l��ģʽ��(sh��)
����3��1����FP-tree�Ķ��x�c��(g��u)��
��������FP-tree���ڂ��y(t��ng)FP-tree�Ļ��A(ch��)��ͨ�^(gu��)���M(j��n)�@�õġ�
�������x2�����l��ģʽ��(sh��)(OFP-tree)��һ�N��(sh��)�Y(ji��)��(g��u)�����x���£�
����(1)������������(g��)���ֽM�ɣ�һ��(g��)��(bi��o)ӛ��“null"�Ę�(sh��)����һ�����(xi��ng)ǰ�Y�Ә�(sh��)�������(sh��)���ĺ������M�ɵĘ�(sh��)���Լ�һ��(g��)�l���(xi��ng)�^����
����(2)�(xi��ng)ǰ�Y�Ә�(sh��)�е�ÿ��(g��)�Y(ji��)�c(di��n)��6��(g��)��M��:item-no,count,parent-link,child-link,last-link��node-link�����У�item-noӛ�ԓ�Y(ji��)�c(di��n)���������(xi��ng)���(xi��ng)�^���е���̖(h��o)��countӛ䛏ĸ��Y(ji��)�c(di��n)��ԓ�Y(ji��)�c(di��n)��·�������������(xi��ng)�������Д�(sh��)��(j��)��(k��)��(w��)�г��F(xi��n)�ĴΔ�(sh��)��parent-link��ָ�Y(ji��)�c(di��n)��ָᘣ�child-link��ָ���һ��(g��)�ӽY(ji��)�c(di��n)��ָᘣ�last-link��ָ��������ĺ��ӽY(ji��)�c(di��n)����node-link�t�B�ӵ�FP-tree���cԓ�Y(ji��)�c(di��n)������ͬitem-no����һ��(g��)�Y(ji��)�c(di��n)������](m��i)����һ�Y(ji��)�c(di��n)���t��null��������ͬ���Y(ji��)�c(di��n)�ĽY(ji��)�c(di��n)����item-no��С����Ĵ������С�
����(3)�l���(xi��ng)�^���е�ÿ��(g��)�(xi��ng)�Ƀɂ�(g��)��M�ɣ�item-no(�Y(ji��)�c(di��n)���������(xi��ng)��)��node-link���^ָ�(ָ��FP-tree�о���item-name��(du��)��(y��ng)item-no�ĵ�һ��(g��)�Y(ji��)�c(di��n))���(xi��ng)�^���е��(xi��ng)��������F(xi��n)�l�ȵĽ������С�
����OFP-tree�cFP-tree��֮ͬ̎��Ҫ���ڣ�(1)FP-tree�еĽY(ji��)�c(di��n)�������item-name����OFP-tree�еĽY(ji��)�c(di��n)�������item-no����ݔ��ģʽ�r(sh��)�Ō�item-no�Q��item-name��(2)FP-tree�еĽY(ji��)�c(di��n)�ǟo(w��)��ģ���OFP-tree�еĽY(ji��)�c(di��n)�ǰ���item-no��С����Ĵ������еġ�
����3��2�㷨��(sh��)��
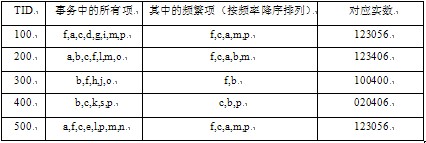
������1�O(sh��)��(w��)��(sh��)��(j��)��(k��)�е���(w��)���1��ʾ����С֧�ֶ��ֵ��3��
����
������1һ��(g��)��(w��)��(sh��)��(j��)��(k��)ʾ��
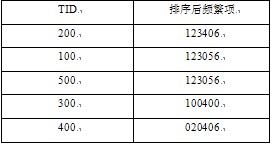
������2ͨ�^(gu��)�����õ�����(sh��)��(j��)��(k��)D*
 ����
����
����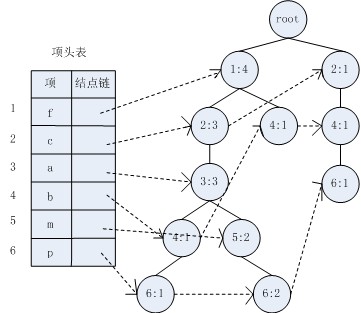
�����D1��(w��)��(sh��)��(j��)��(k��)D*��(du��)��(y��ng)��OFP��(sh��)
����
�����㷨1��OFP-tree�Ľ���
����ݔ�룺һ��(g��)��(w��)��(sh��)��(j��)��(k��)D����С֧�ֶ��ֵminsup
����ݔ����������������l��ģʽ��(sh��)OFP-tree
������������(zh��)�����²��E
������1�� ������(w��)��(sh��)��(j��)��(k��)Dһ�飬�@���l��1-�(xi��ng)������֧�ֶ���Ϣ�����l��1-�(xi��ng)������֧�ֶȽ������У�ӛ��L(zh��ng)��
������2�� �ڶ������D����trans�е�ÿ��(g��)�l���(xi��ng)��L��������У������(xi��ng)����L�е���̖(h��o)��Q�������ڵ��(xi��ng)��0��(l��i)�a(b��)λ��
������3�� ����Q�õ�������(w��)����(sh��)��(sh��)��С���õ�һ��(g��)�µĔ�(sh��)��(j��)��(k��)D*��
������4�� ��(chu��ng)��SFP-tree�ĸ��Y(ji��)�c(di��n)T��ӛ��“null”����(du��)��D*�е�ÿ��(g��)trans��(zh��)�����²�����
������1�O(sh��)���к�ĽY(ji��)�����p|P��,����p�ǵ�һ��(g��)�(xi��ng)Ŀ,��P��ʣ���(xi��ng)Ŀ�б�;
������2�{(di��o)��insert_tree([p|P],T),���T�](m��i)���ӽY(ji��)�c(di��n)���tN.item-no=p,N.count=1,N�ĸ��Y(ji��)�c(di��n)�ָ��T;��t,��p�cT�������ӽY(ji��)�c(di��n)�M(j��n)�б��^�����N.item-no=p���tN��Ӌ(j��)��(sh��)��1����t����(chu��ng)��һ��(g��)�½Y(ji��)�c(di��n)N��ʹN.item-no=p,N.count=1����T��last-linkָ��N��N�ĸ��Y(ji��)�c(di��n)�ָ��T��
������3����¼����˽Y(ji��)�c(di��n)N���t��N���뵽�(xi��ng)�^���е�p��(g��)Ԫ�ص���ͬ�Y(ji��)�c(di��n)朱���ĩβ.
������4���P�ǿգ��t�f�w�{(di��o)��insert-tree(P,N)��
������Ҫָ�����ǣ���OFP-tree�У�������ͬ���Y(ji��)�c(di��n)���ӽY(ji��)�c(di��n)������ģ��ڼ����½Y(ji��)�c(di��n)�r(sh��)ֻ��Ҫ���^�����ӽY(ji��)�c(di��n)��item-no����FP-tree�t��Ҫ���^���нY(ji��)�c(di��n)�����ԣ�OFP-tree����һ��(g��)�½Y(ji��)�c(di��n)�ĕr(sh��)�g��͡����ң�item-no����ԓ�(xi��ng)���(xi��ng)�^���е�λ�ã�����Ҫ�M(j��n)�в��ҡ�
�����㷨2��OFP-growth
����ݔ�룺���ɵ�OFP-tree��minsup
����ݔ�����{(di��o)��OFP-growth(OFP-tree,null)
�����������{(di��o)��OFP-growth(OFP-tree,null)
����ProcedureOPF-growth(T,a)
����{
����(1) if��(sh��)T������һ·��P
����(2) then��(du��)·��P�е���һ�(xi��ng)���M��β��ݔ���(xi��ng)��βα(�D(zhu��n)�Q��item-name)���(xi��ng)��֧�ֶ�ȡβ�нY(ji��)�c(di��n)����С֧�ֶ�
����(3) else{
����(4) for(i=n;i>=0;i--)//n���(xi��ng)�^�����L(zh��ng)�Ȝp1
����(5) {β=��sup(β)=sup(i);
����(6) ��(g��u)��β�ėl��FP-treeTβ;
����(7) ifTβ≠φthencallSFP-growth(Tβ,β);
����(8) }}}
�����������㷨���Կ������ڲ���һ��(g��)�µĽY(ji��)�c(di��n)�r(sh��)������Ҫ��?g��u)��?xi��ng)�^���ĵ�һ�(xi��ng)�_(k��i)ʼ���^������ͬ�(xi��ng)���ĽY(ji��)�c(di��n)����B��ֻ��Ҫ����(j��)��̖(h��o)�Ϳ��Ժܿ���ҵ���Ҫ朽ӵĽY(ji��)�c(di��n)λ�á�ͬ�r(sh��)����(sh��)��(j��)��(k��)�Ļ��A(ch��)�ϣ����Բ�������(g��)���^ԓ���Y(ji��)�c(di��n)�ĸ��ӽY(ji��)�c(di��n)�Ƿ��cҪ����ĽY(ji��)�c(di��n)��ͬ��ֻ����^������ĽY(ji��)�c(di��n)���ɡ��@�Ӿʹ��p�����l��ģʽ��(sh��)�Ą�(chu��ng)���r(sh��)�g�����@�ɷ��棬ԓ�㷨�^ԭ�㷨����һ������ߡ�
����4�Y(ji��)Փ
����ͨ�^(gu��)��(du��)�l��ģʽ���L(zh��ng)�㷨��Ԕ��(x��)�˽⣬���Կ���ԓ�㷨���������㷨�����߂�ă�(y��u)�c(di��n)��������Ҳͬ�Ӵ���һЩȱ�ݡ�������FP��growth�㷨�У��^�֕r(sh��)�g��Ҫ��������FP��tree���l��FP��tree�Ę�(g��u)���c��v�ϣ��mȻ���Č�(du��)��(chu��ng)����(sh��)���㷨�M(j��n)����һЩ���M(j��n)��������Ȼ���ںܴ�ĸ��M(j��n)���g��
���������īI(xi��n)
����[1]��ϲ�O(p��ng).����Fp-growth�㷨���P(gu��n)(li��n)Ҏ(gu��)�t�ھ��㷨�о��c��(y��ng)��[D].����:���ϴ�W(xu��),2006:1
����[3]���f.�����P(gu��n)(li��n)Ҏ(gu��)�t�Ĕ�(sh��)��(j��)�ھ��㷨�о�[D].����:�������I(y��)��W(xu��),2009:18
����[4]����,��С��.��(sh��)��(j��)�ھ�����c���g(sh��)[M].����:�C(j��)е���I(y��)������,2007.3:155~156.
����[6]������,���Pռ,�S��.��(sh��)��(j��)�ھ���Փ�c��(y��ng)��[M].����:���A��W(xu��)�����磻������ͨ��W(xu��)������,2008.4:115~120.
����(bi��o)�}����Ч�����l��ģʽ��(sh��)���㷨�о�
�D(zhu��n)�dՈ(q��ng)ע����(l��i)�ԣ�http://www.56st48f.cn/fblw/dianxin/yingyong/6920.html
���P(gu��n)��(w��n)�}���
�zӰˇ�g(sh��)�I(l��ng)��AHCI�ڿ����]��Phot...�P(gu��n)ע:106
Nature���¶��W(xu��)���ӿ�Nature Com...�P(gu��n)ע:152
��С�W(xu��)�̎�ֵ���˽⣬�@Щ�����W(xu��)...�P(gu��n)ע:47
2025�ꌑ(xi��)����W(xu��)Փ�Ŀ����õ�19��(g��)...�P(gu��n)ע:192
�y(c��)�L�I(l��ng)��Ƽ������ڿ��x�� �p����...�P(gu��n)ע:64
���r(sh��)�_(k��i)Փ�ęz���C������Ҫ�P(gu��n)ע:52
�Ї�(gu��)ˮ�a(ch��n)�ƌW(xu��)�ڿ��Ǻ����ڿ����P(gu��n)ע:54
��(gu��)�H����(sh��)��Ҫ�˽�Ć�(w��n)�}����P(gu��n)ע:58
��������(sh��)�ܷ��u(p��ng)�Q���P(gu��n)ע:48
��ŌW(xu��)����Щ��Ͷ���SCI�ڿ���ֵ...�P(gu��n)ע:66
ͨ�Ź����ИI(y��)Փ���x�}�P(gu��n)ע:73
SCIE��ESCI��SSCI��AHCI�ڿ�Ŀ�...�P(gu��n)ע:121
�u(p��ng)�Q�l(f��)Փ�ĺ�߀�dz���(sh��)���P(gu��n)ע:68
��(f��)ӡ��(b��o)���Y����Ҫ�D(zhu��n)�d��(l��i)Դ�ڿ���...�P(gu��n)ע:51
Ӣ���ڿ����峣Ҋ(ji��n)��Փ�Ġ�B(t��i)����...�P(gu��n)ע:69
Web of Science ���ĺϼ��ڿ��u(p��ng)��...�P(gu��n)ע:59
�����ϢՓ�ķ���
���ܿƌW(xu��)���g(sh��)Փ�� �V���ҕՓ�� ��늼��g(sh��)Փ�� Ӌ(j��)��C(j��)��Ϣ����Փ�� Ӌ(j��)��C(j��)�W(w��ng)�j(lu��)Փ�� Ӌ(j��)��C(j��)��(y��ng)��Փ�� ͨ��Փ�� ��Ϣ��ȫՓ�� ��ӑ�(y��ng)��Փ�� ��Ӽ��g(sh��)Փ�� �����t(y��)�W(xu��)����Փ�� ܛ���_(k��i)�l(f��)Փ��

SCI�ڿ�����
- MEASUREMENT SCIENCE and TECHNOLOGY�п�Ժ�օ^(q��)
- MEAT SCIENCE�ڿ������п�Ժ�օ^(q��)
- MECCANICA�п�Ժ�ׅ^(q��)
- MECHANICAL ENGINEERING�п�Ժ�օ^(q��)
- MECHANICAL SYSTEMS AND SIGNAL PROCESSING�ڿ������п�Ժ�օ^(q��)
- MECHANICS OF MATERIALS�ڿ������п�Ժ�օ^(q��)
- Mechanics of Solids�п�Ժ�օ^(q��)
- MECHANICS OF TIME-DEPENDENT MATERIALS�ڿ������п�Ժ�օ^(q��)
- MECHANISM AND MACHINE THEORY�п�Ժ�ׅ^(q��)
- MECHATRONICS�s־���п�Ժ�ׅ^(q��)