�����W�j��Փ��ˮ�|�u�rģ�͵ı��^�о�
���ٙ�Ŀ��ˮ��Փ�� �l�����ڣ�2010-09-01 14:33 ��ȣ�
����ժҪ��������MATLAB�W�j�������ƽ�_��������BP-LM��LVQ�ɷN�ر�ˮ�W�jˮ�|�u�rģ�͡��о��Y��������BP-LM�W�j��Ӌ���ٶȺ��Ք��ٶ��h����LVQ�W�j��BP-LM�W�jģ�ͱ��^�m����ˮ�|�u�r������Ҳ�^���˴�С�ӱ����W�jģ��Ӗ����Ӱ푣��l�FLVQ�W�jģ�Ͳ��m���ô�Ӗ���ӱ��M��Ӗ������BP-LM�W�j��Ӗ���ӱ��Ĵ�С�����У��@�����ژ����������д����Ե�Ӗ���ӱ���
�����P�I�~���˹��W�j��BP-LM�W�j��LVQ�W�j��Ӗ���ӱ���ˮ�|�u�r
����
����1ǰ��
����ˮ���������Ͱlչ�����|���A���S�����a�İlչ���˿ڵ����L��ˮ�YԴ��ȱ��ˮ�|��Ⱦ���}Խ��Խͻ����ˮ�h���|���u�r���J�R���о�ˮ�h����һ���Ҫ���ݣ���Ŀ���ǜʴ_��ӳ�h�����|������Ⱦ��r���A�yδ���İlչڅ�ݣ���ˮ�h���������o��������һ���Ҫ���A�Թ�����ˮ�h���|���u�r��ָͨ�^��ˮ�w��һЩ���������W������ָ�˵ıO�y���{�飬������ͬ��Ŀ�ĺ�Ҫ��һ���ķ�����ˮ�w���|��������Ӌ��ͨ�^��ˮ�|�M���u�r���_������Ⱦ��ͣ��ʴ_��ָ��ˮ�w���r����Ⱦ�̶ȣ��鱣�oˮ�w��ˮ�|�ṩ�����ԡ�ԭ�t�Եķ�����������
��������Ӱ�ˮ�|�����غܶ࣬�������cˮ�|e֮�gͨ�����ڏ��s�ķǾ����Pϵ����������]��һ�N�yһ�ĺ��J���u�r������Ŀǰ������ˮ�|�u�r�ķ����lչ�˺ܶ࣬����ǻ��ڂ��y���W���yӋ�W����ģ�����W�ͻ�ɫ���W���u�rģ�ͣ�������Ⱦָ�������C����Ⱦָ������ģ���C���u�з�����ɫ�P�ȷ���������ɫ�քݛQ�߷�����Ԫ��������[1-2]�������Ⱦָ����ֻ���u�rˮ�w��ij�N��Ⱦ���Σ���̶ȣ����ܷ�ӳˮ�w�и��N��Ⱦ��ľC��Ӱ푣��C����Ⱦָ��������һ�����εĔ���ָ������Ӳ�Խ��ޣ���ҕ���@�N���ּ�����ģ���ԣ�������ģ�����W�ͻ�ɫ���W�ľC���u�r�������mȻע����@�N���H�ϴ��ڵķ��ּ���ģ���ԣ����ڸ�ˮ�|��Ⱦ��ָ�˙��ص��x���ϳ��������^�Ժ��S���ԣ��������һ���ľ����ԡ�
�����˹��W�j��ArtificialNeuralNetwork�����QANN������Դ��20���o40�������80���ȡ��ͻ�Ʋ�Ѹ�ٰlչ�͏V�������ڱ����W�ƵķǾ���ģ�M���g����Ŀǰ����S��ǰ�ؿƌW֮һ��ANN�nj����X��Ԫ��ϵ�y�������������ܵij����ģ�M���������m�����ԌW�������c���dz��m�����о��ͽ�Q���s�ķǾ��Ԇ��}��
������80���ĩ�_ʼ���҇��ĭh�����o�������_ʼ���W�j���g����h���|���u�r�����������˻����`��������BP���W�j�����շƠ��£�Hopfield���W�j�������������RBF���W�j���ԽM������ӳ�䣨SOFM���W�j���W������������LVQ���W�j�Ȕ�10��N�u�rģ�ͣ�������80-90%�ǻ���BP�W�jģ�ͼ���׃��ģ��[2]��
�������о�ᘌ��ر�ˮ�h���|���u�r����MathWorks��˾�_�l��MATLAB��R14SP1���W�j�����䣨4.0.4�汾����ƽ�_�������˻���Levenberg-MarquardtӖ���㷨��BP�W�j���u�rģ�ͣ�BP-LM���ͻ���LVQ�W�j���u�rģ�ͣ�LVQ�����քe�ô�Ӗ���ӱ���СӖ���ӱ��M��Ӗ�����Ùz�y�ӱ��u�rӖ��Ч�����W�jģ�͵����ܣ����^������СӖ���ӱ����W�jģ��Ӗ����Ӱ��Լ��ɷNģ�͵ă��ӡ�
����2Ӗ���ӱ��Ĝʂ�
�������W�jģ�͵Ľ���֮�У�Ӗ���ӱ�ռ�зdz���Ҫ��λ�á����M��ģʽ�R�e���^���У���Ҫ������Ӗ��֮�Ы@�õę��أ��@��ֱ��Ӱ푔�����̎���c���ĽY������һ����W�j�M�Ќ���У����õ���С�ӱ��ķ������@ʹ������ģ����Ӗ���W�����^�̺����ˣ�Ҳʹ��ģ�Ͳ��܉�õ�����Ĕ�����֧�����ĽYՓ���W�j�ַQ���˹����ܣ���Ҫ��������������˞�o���Ĕ����У������ČW�������ҽo���Ĕ���֮�g��ϵ�c�Pϵ���Ķ��M�����o���Ĕ����ķ������˞�o���Ĕ��������٣��t�����W�j�o���õ���Ч��Ӗ���͌W�����Ķ�������ж������ķ���ϴ���һ����ƫ���ԡ�
����2.1�ر�ˮ�h���|���u�r�˜�
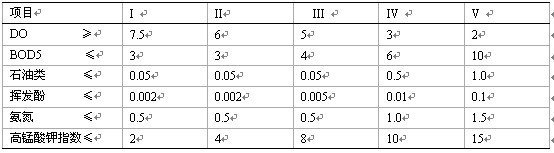
�������Ę˜ʲ���2002��6��1�Ռ�ʩ��ˮ�|�u�r�˜�GB3838-2002���u�r�˜ʣ��������ژ˜��е�DO��BOD5��ʯ����]�l�ӡ����������i���ָ�����@6�ָ�������u�r�Ŀ�����w�˜�Ҋ��1��
������1�ر�ˮ�h���|���˜ʣ�GB3838-2002����λ��mg/L��
����  ����
����
����2.2�z�y�ӱ�
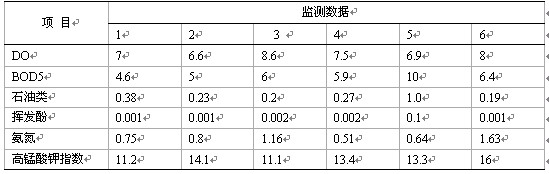
�����ڌ��Ĕ����ϣ�������xȡ�����īI[2]�е�ˮ�|�O�y�Y������z����Ҋ��2��
������2�z�����mg/L��
��������2.3Ӗ���ӱ�
��������С�ӱ�ֱ��ʹ��ˮ�|�˜ʣ����ڶ��Sƽ��ȵ�ͶӰ�ֲ�Ҋ�D1��
������ӱ�����MATLAB�ṩ��RAND�����ڸ����u�r�˜ʃȰ��S�C����ֲ���ʽ���β�����Ӗ���ӱ���ÿ������200���ӱ���������1000��Ӗ���ӱ���������Ŀ��ݔ����ՓֵI����1��II����2������������ơ����ڶ��Sƽ��ȵ�ͶӰ�ֲ�Ҋ�D2
��������BP-LM�W�jģ�ͣ����u�r�Y������I��ˮ�|��ݔ�룬����ݔ�����飰����֮�g�Ĕ�ֵ�������u�r�Y������II��ˮ�|��ݔ�룬����ݔ������1��2֮�g�Ĕ�ֵ������������ơ�
��������LVQ�W�jģ�ͣ����u�r�Y������I��ˮ�|��ݔ�룬����ݔ�����飱�������u�r�Y������II��ˮ�|��ݔ�룬����ݔ������2������������ơ�
���� 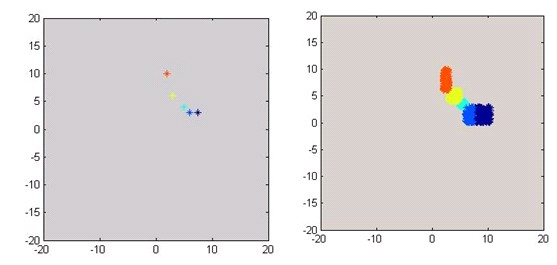
���� �D1СӖ���ӱ��ڿ��g�еķֲ� �D2��Ӗ���ӱ��ڿ��g�еķֲ�
����3BP-LM�W�jģ�͵Ľ���������Y��
����3.1BP-LM�W�j��ԭ���c�Y��
����3.1.1ԭ��
����BP�W�j��������ǰ���W�j����������`����`������㷨(ErrorBackpropagation)��������1986����D.E.Rumelhart���������BP�㷨�Y�����Ρ����ڌ��F��BP�W�j��һ�N���;W�j����ݔ��ӡ��[���ӡ�ݔ���ӽM�ɡ����c��֮�g����ȫ���B��ʽ��ͬһ�ӵĆ�Ԫ�t����B�ӣ�ݔ��Ӻ�ݔ���ӵĆ�Ԫ�����ɾ��w���}��ݔ��Ӆ�����ݔ���Ӆ������_���ģ����[���ӵĆ�Ԫ���t�ɾ��w���}�ď��s�̶ȡ��`���½���r�ȁ��_���������\�ЙC���ǣ�����Ϣ����������`������2���^�̽M�ɣ�����ԭ��ԔҊ�īI[3-6]��
����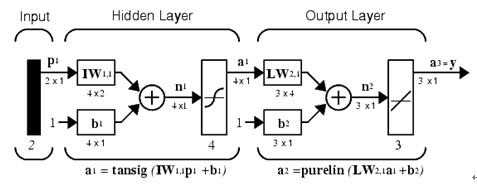
���� �D3BP�W�j�ĽY��
�����D3����ʾ��BP�W�jģ�ͣ�ݔ���2�S������1���[���ӣ�4���[����Ԫ�����f������tansig��ݔ����3����Ԫ�ĽY�������f������purelin��
������ݔ��ģʽӳ�䵽�������������֪�R�ə�ֵ���w�F����������o�����}��ę�ֵ��δ֪�ģ�ֱ���ҵ����Ù�ֵ֮ǰ���W�j���ܽ�Q�@�����}���������Ù�ֵ���ϵ��^�̣��Q��Ӗ�����ڽ�B�W�jģ�͵�Ӗ��֮ǰ������һ�����Ŀ�˾W�j�`��������W�j�Ք���������ֵ�ij̶ȵĶ���ֵ��
����Ӗ�����E�ɚw�{���£�
������1�� ��ʼ�����x���Y�������ľW�j�������п��{����(���غ�ƫ��)�����ֲ����^С��ֵ��
������2�� ��ÿ��ݔ��ӱ���ǰ��Ӌ�㣻
������3�� ������̎���_��Ŀ�˾W�j�`��r��Ӗ���ꮅ����֮�t�M�з���Ӌ�㣬����ݔ��ӱ��ٴ�ݔ�����ǰһ��Ӌ���еõ������ę���һ��Ӗ�����ٴ��������ء�
�����@�ӣ������W�j���^Ӗ���͌W���������b�e�������ڽo��һ����ʾݔ��ģʽ����һϵ�������M�ɵ�ݔ��������Ӗ���^�ľW�j�Ϳ������鏊�R�e����ʹ�á�
���������������ľW�jģ�́����^��BP�W�jҪ����Ķ࣬�����Ć��}Ҳ�������^ͻ���������Ք��ٶ����Լ��������^�ֲ���Сֵ�Ć��}���@Щ����ͨ�^Levenberg-Marquardt�����QLM���㷨����Q��
�����OX(k)��ʾ��k�ε����ę�ֵ��ƫ�����M�ɵ��������µę�ֵ��ƫ���M�ɵ�����XK+1�ɸ��������Ҏ�t��ã�
����XK+1��X(K)ʮ��X(1)
��������ţ�D���t�ǣ�
������X��-[��2E(x)]-1-��E(x)(2)
����(2)ʽ�Ш�2E(x)��ʾ�`��ָ�˺���E(x)��Hessian��ꇣ���E(x)��ʾ�ݶȡ�
�����O�`��ָ�˺����飺
����E��X��=1/2ΣNi=1ei2(x)(3)
����(3)ʽ��e(x)���`���ô��
������E(x)=JT(x)e(x)��4��
������2E(x)=JT(x)e(x)+S(x)��5��
�����ڣ�4������5��ʽ��S(x)=ΣNi=1ei(x)��2ei(x)��Jacobian��ꇡ�
�������ڸ�˹-ţ�D����Ӌ�㷨�t�У�
������X��-[JT(x)JT(x)]-1JT(x)e(x)(6)
����LM�㷨��һ�N���M�ĸ�˹-ţ�D����������ʽ�飺
������X��-[JT(x)JT(x)+μI]-1JT(x)e(x)(7)
�����ģ�7��ʽ�ɿ������������ϵ��μ=0���t���˹-ţ�D�������μȡֵ�ܴtLM�㷨�ӽ��ݶ��½�����ÿ�����ɹ�һ�����tμ�pСһЩ���@���ڽӽ��`��Ŀ�˵ĕr����u�c��˹-ţ�D�����ơ���˹-ţ�D���ڽӽ��`�����Сֵ�ĕr��Ӌ���ٶȸ��죬����Ҳ���ߡ�����LM�㷨�����˽��ƵĶ��A������Ϣ�������ݶ��½�����ö࣬���`�C��������LM�㷨�����^ԭ�����ݶ��½�������ٶȎ�ʮ�����ϰٱ�����������[JT(x)J(x)+μI]�������ģ�����(7)ʽ�Ľ⿂�Ǵ��ڵġ����@�����x���f��LM�㷨Ҳ���ڸ�˹-ţ�D������錦�ڸ�˹-ţ�D�����f��JTJ�Ƿ�M��߀�ǂ����ڵĆ��}���ڌ��H�IJ����У�μ��һ��ԇ̽�Եą��������ڽo����μ�������õġ�x��ʹ�`��ָ�˺�����E(x)���ͣ��tμ���ͣ���֮���tμ����[7]��
����3.1.2�W�jģ�ͽY��
�����W�jݔ���6�S����������һ���[���ӣ�13����Ԫ�����f������tansig��ݔ����1����Ԫ�����f��������purelin��
�����W�jӖ��������tainlm��MATLAB�Ќ��FLMӖ���㷨�ĺ��������W�j���ܺ�����MSE����Ŀ��ֵ��1e-5������������Epochs=1000����MATLAB�S�C���֮a������ʼ��B�Þ�0���̶��@��׃�����أ���
�������[������Ԫ���x���ϣ���Փ�C�������һ���[����������Ĺ��c���Ϳ����_��������R�e���ȡ���ˮ�|�u�r���}�ϣ����h����һ���[���ӡ��[������Ԫ�����xȡ�Пo��Փ�ϵ�ָ����һ���Ǹ�������xȡ�������[����BP�W�j�����õĹ��㷽����[8,9]��
����N=MNz/(Nx+Nz)��N2≥NxNz��N=log2M��N2=MNz
����ʽ�У�N���[������Ԫ����M��W���ӱ�������Nx��Nz�քe��ݔ�롢ݔ���ӹ��c�������W���ӱ���������r������ʽ�_����N����ƫС���y���M�зǾ����R�e����ˣ�Ny���x���Դ�һЩ��Nֵ�����xȡ�����m?������ԇ�㣬�����^����[�����_ʼ��Ȼ������m���ᗉ������^�ٵ��[���ӹ��c���l����u�Ӷࡣ�ڱ�����У���������ԭ�t���Ȱ���ʽ���㣬Ȼ���xȡ����N��һϵ��ֵ����ģ�����M�Мyԇ���Y���@ʾ������Ԫ����ȡ13�r��Ч����á�
����3.2BP-LM�W�jС�ӱ�Ӗ�����Y��
����3.2.1Ӗ���^��
�����W�j���^7���������ڵ�Ӗ�������ܺ����½���8.2653e-6��С����Ŀ��1e-5��Ӗ���Y����Ӗ���^����D4��ʾ��
���� 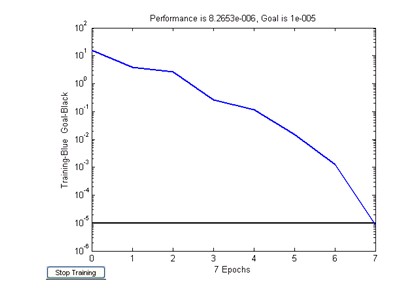
�����D4BP-LM�W�jС�ӱ�Ӗ���^���оW�j�����½�����
����3.2.2�W�jģ�͵ķ���Y��
������ˮ�|�u�r�˜ʵĸ����Ⱦָ�˷ֽ�ֵ����1��ݔ����Ӗ���õľW�jģ�ͣ������ľW�jģ��ݔ��ֵ�քe��0.9999��2.0000��3.0000��4.0000��4.9999���@Ȼ��������I-V�ˮ�|��ԓ�W�jģ��ݔ��ֵ�ķ����քe�飺(0��0.9999]��(0.9999��2.0000]��(2.0000��3.0000]��(3.0000��4.9999]�ͣ�4.9999��
������3С�ӱ�Ӗ����ģ�͌��z�y�ӱ����u�r�Y��

�������z�y�ӱ�ݔ��W�jģ�ͣ��õ���ݔ���քe��3.2999��3.3591��3.4745��3.1613��3.2450��3.9969����������4�ˮ�|���@�cģ���C���u�з���Y��һ��[10]��Ҋ��3����
����3.3BP-LM�W�j��ӱ�Ӗ�����Y��
����3.3.1Ӗ���^��
�����W�j���^68���������ڵ�Ӗ�������ܺ����½���6.60625e-6��С����Ŀ��1e-5��Ӗ���Y����Ӗ���^����D5��ʾ��
���� 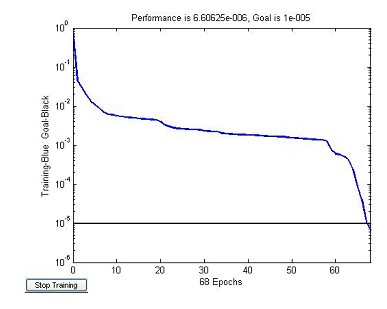
���� �D5BP-LM�W�j��ӱ�Ӗ���^���оW�j�����½�����
����3.3.2�W�jģ�͵ķ���Y��
������ˮ�|�u�r�˜ʵĸ����Ⱦָ�˷ֽ�ֵ����1��ݔ����Ӗ���õľW�jģ�ͣ������ľW�jģ��ݔ��ֵ�քe��1.9819��2.3773��3.0298��4.5679��5.0000���@�ӣ�������I-V�ˮ�|����W�jģ��ݔ��ֵ�ķ����քe�飺(0��1.9819]��(1.9819��2.3773]��(2.3773��3.0298]��(3.0298��5.0000]�ͣ�5.0000��
�������z�y�ӱ�ݔ��W�jģ�ͣ��õ���ݔ���քe��3.0413��3.9996��2.9994��3.9669��3.9827��3.9996������1��2��4��5��6헙z�y�ӱ�����IV���3헌���III��@�cģ���C���u�з���Y�����в�e��Ҋ��4����
������4��ӱ�Ӗ����ģ�͌��z�y�ӱ����u�r�Y��

����4.LVQ�W�j
����4.1LVQ�W�j��ԭ�������c�W�jģ�ͽY��
����4.1.1LVQ�W�j��ԭ���c����
����LVQ�W�j�����W���������W�j(LearnVectorQuantization).�W�j�ĽY��ʾ��DҊ�D6��
����LVQ�W�j�ЃɌӽM�ɣ���һ�Ӟ鸂���ӣ��ڶ��Ӟ龀�Ԍӡ��������܉�W����ݔ�������ķ���@�c�ԽM�������W�j�dz����ơ����Ԍӌ������ӂ����ķ����Ϣ�D׃�ɞ�ʹ���������x��e�����Ԍ������ӌW���õ���Q����������Ԍ����õ���Q��Ŀ���
����LVQ�㷨�nj�SOM��Self-OrganizingMaps���ԽM��ӳ�䣩�㷨��һ�N�Uչ�����Ļ���˼��Դ��SOM�㷨���������ľW�j�Y���cSOM�����ƣ���������SOM�W�j�ǘӴ���ij�N�ض����ؓ�Y����LVQ�㷨��һ�N�O���͵ľ������ԓ�㷨�cSOM�㷨���ą^�e�����ṩ�oLVQ�W�j��ÿ��Ӗ��������һ��“��ӛ”(1abel)��ԓ“��ӛ”����ָ��ÿ��Ӗ�������ٵ�e���ھW�j��Ӗ���^������һ���ıO�����á���ˣ�LVQ�㷨���H����SOM�㷨����˼���ڱO���W���I���е�һ�N���ã���Kohonen���бO���W���ĔUչ��ʽ���ں����ԽM�����Ќ����O���ļ��g���W�������Ǹ����ģ����a����ʽ���н̎��O���ģ�Ҳ�����f�������W��������Ӗ��ݔ��ָ���ĸ���оֲ��M�С�
���� 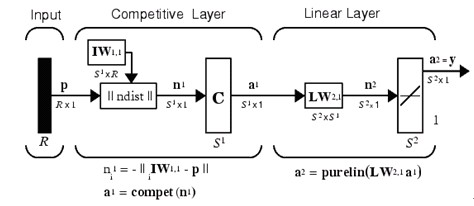
���� �D6LVQ�W�j�Y��
����LVQ�㷨���ڱO����B���������M��Ӗ�����ڸ������оW�j�������o����ݔ�롢ݔ�������ԄӌW���m���ӱ����Բ���ݔ��ӱ��������w�Ĺ������E�飺
������1��ÿݔ��һ���ӱ�X����ݔ��������ҳ��������Ć�ԪC��
������2���OX����e��֪��ң����ڵ�һ�A�ΌW���Уõ�e��ӣ��t��ֵ�����¹�ʽ�{����
����wc(t+1)=wc(t)+u(t)[x(t)-wc(t)]r=s
����wc(t+1)=wc(t)-u(t)[x(t)-wc(t)]r≠s
����wi(t+1)=wir≠s
��������ʽ��Ҋ����x�����_���tʹ�õę�������أ���t�t�h�x�����������ݔ���Ć�Ԫ����ֵ���ӡ�
����LVQ�W�j��Ӗ���^�����£�
������1�� ��ʼ�����������O�ó�ʼ�W���ʣ�
������2�� ��Ӗ�������xȡһݔ������X���ҳ��cX������СEuclidean���x�ę�����WK��
������3�� �{����Ԫk�ę�������
������4�� Ӗ�������xȡ����һ��ݔ�������ṩ�oLVQ�W�j�����ز��E2)ֱ�����е��������ṩ��һ���ֹ��
������5�� �pС�W����α�����Ҝyԇֹͣ�l���Ƿ�M�㣬����M��tֹͣӖ������t���ز��E2)��
����Ԕ����LVQ�W�j��Ӗ���㷨��Ҋ�����īI[11-12]��
����4.1.2LVQ�W�jģ�͵ĽY��
�����W�jݔ���6�S�����������Ӳ���15����Ԫ��ݔ���Ӟ�Ҫ��ݔ��������ʽ������ģʽ����MATLAB�в����D�Q������ind2vec�������e�����D�Q������ģʽ���W�j���ܺ�����MSE����Ŀ��ֵ��1e-5������������Epochs=1000����MATLAB�S�C���֮a������ʼ��B�Þ�0���̶��@��׃�����أ�����������Ԫ��Ҳ���ڲ����������Ļ��A�ϱ��^��ȱ�c�����_����15������ѡ�
����4.2LVQ�W�jС�ӱ�Ӗ���c�Y��
����4.2.1�W�jģ�͵�Ӗ��
�����W�j���^553���������ڵ�Ӗ�������ܺ����½���С����Ŀ��1e-5��Ӗ����ɡ�Ӗ���^����D7��ʾ��
����4.2.2�W�jģ�͵ķ���Y��
������ˮ�|�u�r�˜ʵĸ����Ⱦָ�˷ֽ�ֵ����1��ݔ����Ӗ���õľW�jģ�ͣ������ľW�jģ��ݔ���Y�����D�Q����vec2ind�D�Q���������Փ�Y������1��2��3��4��5���քe������I��V�ˮ�|�����Hݔ���Y���c����ȫһ�¡����z�y�ӱ�ݔ��W�jģ�ͣ�ͬ�ӌ�ݔ���Y�������D�Q����vec2ind�D�Q��������Y���քe��3��3��3��3��3��5����ǰ��헙z�y�ӱ����u�r�Y����III�ˮ�|������헙z�y�ӱ����u�r�Y����V�ˮ�|���@�cģ���C���u�нY������ͬ��
���� 
����
�� ���D7LVQ�W�jС�ӱ�Ӗ���^�̈D
����4.3LVQ�W�j��ӱ�Ӗ���Č��
����4.3.1�W�jģ�͵�Ӗ��
�����W�jӖ����16���������ں����ܺ���ʼ�K��0.004������ʎ��ֱ�����1000�ε������ڣ���Ӗ���Y���rҲδ�½���С����Ŀ��1e-5��Ӗ���^����D8��ʾ��
���� 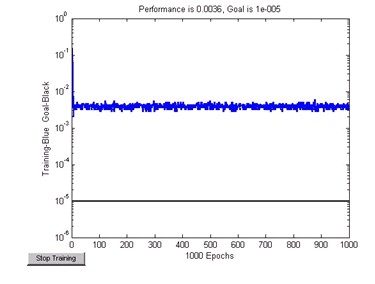
���� �D8LVQ�W�j��ӱ�Ӗ���^�̈D
����4.3.2�W�jģ�͵ķ���Y��
������ˮ�|�u�r�˜ʵĸ����Ⱦָ�˷ֽ�ֵ����1��ݔ����Ӗ���õľW�jģ�ͣ������ľW�jģ��ݔ���Y�����D�Q����vec2ind�D�Q���������Փ�Y������1��2��3��4��5���քe������I��V�ˮ�|�����Hݔ���Y����2��3��3��4��5���@Ȼ��ԓ�W�jģ�͛]�еõ���Ч��Ӗ���������ܲ��ܝM��ˮ�|�u�r��Ҫ��
����5�����cӑՓ
����5.1BP-LM�W�jģ�͵ķ���
��������BP-LM�W�jģ�ͣ�����СӖ���ӱ�Ӗ�����W�jֻ����7�ε������ھ������Ӗ�����Ք��ܿ졣�W�jģ�͌��z�ӱ���ݔ��ֵ�c�A��Ŀ�˽ӽ���Ҳ�cģ���C���u�з�һ�¡�
�������ô�Ӗ���ӱ�Ӗ�������ھW�j�\�����@�����ӣ��W�j���^��68�ε������ڲ����Ӗ�����Ք��ٶ�������С�ӱ�Ӗ��Ҫ��һЩ���W�jģ�͌��ĵ�3헙z�y�ӱ����u�r�Y���cģ���C���u�з��г��룬�W�jģ���u�r��III�ˮ�|����ģ���C���u�з��u�r��IV�ˮ�|��
�����P���W�jģ�͌��z�y�ӱ����u�r�Y���cģ���C���u�з��u�r�Y����һ�����c�����������W�jģ�ͺ����Ի�ʴ_�Ե��u�r���������ģ���C���u�з��ĽY�����˞����ص�Ӱ푺ܴ������^�ԺͲ��_���ԣ����W�jģ�ͻ��������˞�����Ӱ푣������W�jģ����ͨ�^��Ӗ���ӱ��ČW��������ĝ���Ҏ�ɻ�Ҏ�t�����ھW�j���B�ә����С����@һ�c�ρ��f���W�jģ�ͱ�ģ���C���u�з�������ˮ�|�u�r��ԭ����
������ԇ��У�С�ӱ�Ӗ����ģ�͌��z�y�ӱ��o�����u�r�Y���cģ���C���u�з���ȫһ�£�����ӱ�Ӗ����ģ�͌���3헙z�y�ӱ����u�r�Y���c�����u�r�Y����һ�¡������J�鲻�ܓ����Д�С�ӱ�Ӗ���õ���ģ��Ҫ���ڴ��Ӗ���õ���ģ�͡�BP�W�j��Ӗ������Փ����Ҫ�������д����ԵĘӱ����@�ӵõ���ģ�Ͳű��^�ɿ������@Ȼ��С�ӱ����Ǵ����Ե�Ӗ���ӱ�������ӱ��t�w�F�ˌ�����ݔ��ӱ��Ĵ����ԡ�
����������BP-LM�W�jģ�ͷ����^���У�BP-LM�W�j�ă��c�w�F�ĺ����@��
������1�� BP-LM�W�j�����˞�ؿ��]����֮�g�ę�ֵ���ֵ������ͨ�^�ӱ����Hݔ���c����ݔ�����`����^���ČW������,�Ԅӵ��M���{�����m��[13]��
������2�� BP-LM�W�j��ģ���Ρ�Ӌ�����١��ٶȿ죻
������3�� BP-LM�W�j����һ���ķ���������
������4�� �W�j��ͨ�^�W�������_�𰸵Č������Ԅ���ȡ“������”���Ҏ�t���������ԌW��������
������5�� BP-LM�W�j���|�ό��F��һ����ݔ�뵽ݔ����ӳ�书�ܣ������W��Փ���C�������Ќ��F�κΏ��s�Ǿ���ӳ��Ĺ��ܡ��@ʹ�����e�m�������Ȳ��C�Ə��s�Ć��}[14]��
����5.2LVQ�W�jģ�͵ķ���
�����ڱ��Ό���У�LVQ���]�кܺõ��������Ŀ�ˣ���С�ӱ�Ӗ���Č���У��M���\����С����������LVQ�㷨�^BP�㷨���s���W�j�Ք��ٶ�����Ӗ�����^553�ε������ڲŽY��������ӱ�Ӗ����������LVQ�W�j���\�������W�jӖ���ٶȷdz�������CPU��IntelP41.7GHz���ȴ��256MB��Ӌ��C�ϣ����^2��С�r�����1000�εĵ������ڣ����W�j�����ܺ����½������@���hδ�_���A������Ŀ�ˡ�
������Փ�ϣ�LVQ�W�jģ�ͷdz��m�Ͻ�Qģʽ�R�e���}��������ԇ��аl�FLVQ�W�jӖ�����Ք��ٶ��Լ���ˮ�|�u�r���}��̎���Y�����ܲ����롣һ�����f��LVQ�W�j���m�����ô�ӱ���Ӗ������һ���棬LVQ�W�j��Ӗ���ӱ�Ҫ�������Ĵ����ԡ�
����5.3BP-LM�W�j�cLVQ�W�j�Č��ȷ���
������BP-LM�W�j����У��ܺõı��F��BP-LM�W�j�ă��c����������ģ���Ρ�Ӌ�����١��ٶȿ졢�������ҌW��������LVQ�W�j���ڵ����^�࣬�\�㷱������Ҫռ���˴����ăȴ���g��LVQ�W�j��Ŀǰ߀���m����ˮ�|�u�r��������������Ҫ�д����ӱ���Ӗ����ˮ�|�u�r���������֮�£�BP-LM�W�jģ���m����ˮ�|�u�r�������e��Ӗ���ӱ������ܴ����r�¡�
����5.4Ӗ���ӱ��Ĵ����Ԇ��}
����ˮ�|�u�r���W�jģ����Ҫ�������д����Ե�Ӗ���ӱ��M��Ӗ����ֱ�Ӳ���ˮ�|�u�r�˜ʵķֽ�ָ��ֵ����Ӗ���ӱ��������J���@�ӵ�Ӗ���ӱ������д����ԣ�ͬ�r���ӱ�����Ҳ�^�١����IJ����S�C������ֵ���ɵġ�����ֲ��Ĵ�ӱ�����Q��Ӗ���ӱ��Ĵ����Ժ�������Ҫ���ӱ��ľ���ֲ��]�п��]��ˮ�|�u�r�˜ʷּ���ģ���ԡ�����������B�ֲ��Ĵ�Ӗ���ӱ������ܕ���Q�@�����}�����п��ܼӿ��W�jӖ�����Ք��ٶȡ��@�д����Mһ����ԇ����C��
����
���������īI
����[1]������.2003.ˮ�h���|���u�r�Ļ�ɫ�քݛQ�߷�.�Ƽ��c����,3:29-31.
����[2]���ĸߡ���͢��.2003.����BP�W�j��ˮ�|�C���u�rģ�ͼ��䑪��.�h����Ⱦ�������g�c�O��,8(4):23-26.
����[3]ꐹ���.�Ϻ��к������ͺ�Ϳ�YԴ�C���{����.�Ϻ�:�Ϻ��ƌW���g�����磬1988.
����[4]��������.1995.�����e���g϶ˮ�ğo�C�赪�I�B�}���W.����W����17(5):73-80.
����[5]�n�������ݘs�F���S���ܵ�.1986.��ˮ���WҪ���{���փ�.����:��������磬��103-113,121-148.
����[6]����N������Ӣ����.1990.�������I�B���{��Ҏ��.��2��.����:�Ї��h���ƌW������,208-238.
����[7]���w�ꡢ�h���������Ժ���.2004.����LM-BP�㷨�ľC��ˮ�|�u�r�о�.ˮ�YԴ�о�,25(1):12-14.
����[8]�R��ϼ���R�Ծա��w��ȫ.2002.BP�W�j�[���ӌ�ˮ�|�u�r�Y����Ӱ푷���.ˮ���Դ�ƌW,20:(3)16-18.
����[9]�n��Ⱥ.2001.�˹��W�j��Փ���OӋ������.����:���W���I������,123-125.
����[10]���ĸߡ���͢��.2003.����BP�W�j��ˮ�|�C���u�rģ�ͼ��䑪��.�h����Ⱦ�������g�c�O��,8(4):23-26.
����[11]�����`�����Ǭ����־�A.2002.SOM�㷨��LVQ�㷨����׃�w�C��.Ӌ��C�ƌW,29(7):97-100..
����[12]FranciscoS.etal.2002.AssessmentofGroundwaterQualitybyMeansofSelf-OrganizingMaps:ApplicationinaSemiaridArea.EnvironmentalManagement,30(5):716–726.
����[13]�����á����֡�����t.B-P�W�j�����ڵ���ˮˮ�|�O�y�c���x.�Ї��h���O�y.
����[14]����c�������������ĸ�.2003.���ڸ���Փ��BP�W�j��ˮ�|�u�r�c��ɫ�ӑB�A�yģ��.�Ϻ��h���ƌW,22(10):673-681.
����ComparisonStudiesonNeuralNetworkModels
����forWaterQualityEvalutation
����
����Abstract:ThispaperpresentedtwoneuralnetworkmodelsforsurfacewaterqualityevaluationconstructedwithMATLAB7.TheresultsshowedthatthecalculatingvelocityandconvergingvelocityofBP-LMmodelwasfarfasterthanLVQmodel,andBP-LMmodelissuitedtoevaluatewaterquality.Influencesoftrainingsamplesizeontwoneuralnetworkmodelswereobserved.ItisfoundthatLVQmodelwassensitivetotrainingsamplesize,butBP-LMmodeldidn’tso.TherootcauseisthatcalculatingprocessofLVQalgorithmismorecomplicatedthanthatofBP-LMalgorithm.
����Keywords:artificialneuralnetwork;BP-LM;LVQ;trainingsample;waterqualityevaluation
����
����
�����}�������W�j��Փ��ˮ�|�u�rģ�͵ı��^�о�
�D�dՈע�����ԣ�http://www.56st48f.cn/fblw/ligong/shuili/3397.html
���P���}���
�zӰˇ�g�I��AHCI�ڿ����]��Phot...�Pע:105
Nature���¶��W���ӿ�Nature Com...�Pע:152
��С�W�̎�ֵ���˽⣬�@Щ�����W...�Pע:47
2025�ꌑ����WՓ�Ŀ����õ�19��...�Pע:192
�y�L�I��Ƽ������ڿ��x�� �p����...�Pע:64
���r�_Փ�ęz���C������Ҫ�Pע:52
�Ї�ˮ�a�ƌW�ڿ��Ǻ����ڿ����Pע:54
���H������Ҫ�˽�Ć��}����Pע:58
���������ܷ��u�Q���Pע:48
��ŌW����Щ��Ͷ���SCI�ڿ���ֵ...�Pע:66
ͨ�Ź����ИIՓ���x�}�Pע:73
SCIE��ESCI��SSCI��AHCI�ڿ�Ŀ�...�Pע:121
�u�Q�lՓ�ĺ�߀�dz������Pע:68
��ӡ���Y����Ҫ�D�d��Դ�ڿ���...�Pע:51
����Փ�ķ���
�����OӋՓ�� ����Ҏ��Փ�� �V�IՓ�� �C�һ�w��Փ�� ���bՓ�� ��ͨ�\ݔՓ�� ����Փ�� ���Փ�� ˮ��Փ�� �Ԅӻ�Փ�� ܇�vՓ�� ұ��Փ�� ���I�OӋՓ�� �CеՓ��

SCI�ڿ�����
- MEASUREMENT SCIENCE and TECHNOLOGY�п�Ժ�օ^
- MEAT SCIENCE�ڿ������п�Ժ�օ^
- MECCANICA�п�Ժ�ׅ^
- MECHANICAL ENGINEERING�п�Ժ�օ^
- MECHANICAL SYSTEMS AND SIGNAL PROCESSING�ڿ������п�Ժ�օ^
- MECHANICS OF MATERIALS�ڿ������п�Ժ�օ^
- Mechanics of Solids�п�Ժ�օ^
- MECHANICS OF TIME-DEPENDENT MATERIALS�ڿ������п�Ժ�օ^
- MECHANISM AND MACHINE THEORY�п�Ժ�ׅ^
- MECHATRONICS�s־���п�Ժ�ׅ^